

研究方法
外部反馈的应用:不依赖模型自我生成的反馈,研究者使用外部反馈来指导LLM改进翻译。
开放模型的使用:研究中使用了开源的LLaMA-2模型,而不是像GPT-3.5或PaLM-2等这样的闭源模型。
并且研究者考虑到了两种指导语言模型编辑机器翻译错误注释的策略:提示和用指令微调。首先,他们使用不同形式的反馈,以不同的粒度提示LLaMA-2模型。

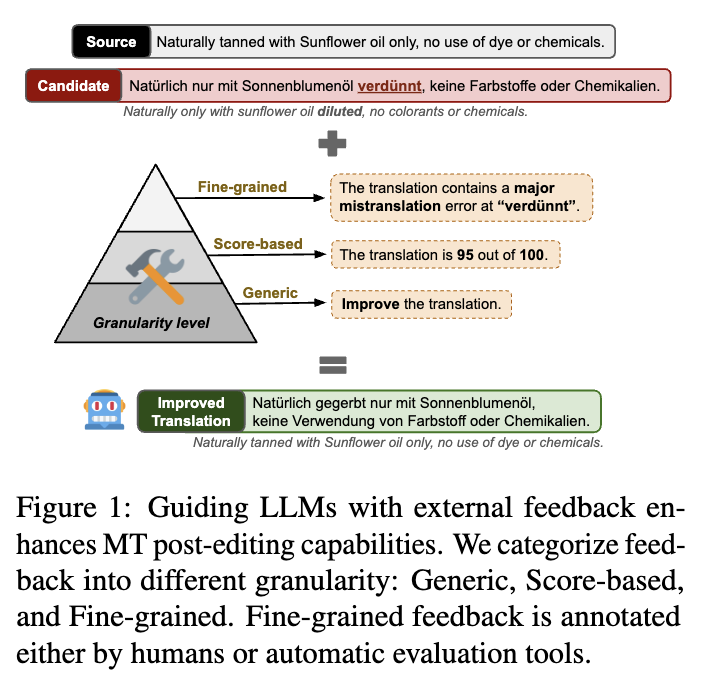
研究采用了三种反馈形式:
一般性反馈:不提供具体细节,没有具体指令,只是提示模型改进初始翻译。
基于评分的反馈:提供一个从0到100的单一MQM评分,反映初始翻译的总体质量。
细粒度反馈:提供具体且详细的错误注释,可能包括错误范围、错误类型和严重程度。这种反馈可以由人工或者自动注释工具进行。
研究发现
在中英、英德和英俄三个语言对上,研究发现使用反馈提示LLM进行翻译编辑可以持续提高机器翻译和译后编辑质量。尽管细粒度反馈在改进输出方面作用有限,但接下来他们用细粒度的错误注释对LLaMA-2模型进行了微调,研究者发现微调带来了“额外的性能提升”。不仅如此,细调后的模型不仅能修复特定错误,还能增强目标语言的自然性。

未来展望
通过这些结果,研究者发现:编辑后的MT输出不需要最大的专有LLM模型,可以用较小的开源模型来完成。他们计划进一步探索如何创建一个可以自动评估任何MT输入的工作流程,并决定是否有必要进行后期编辑以及如何进行后期编辑,以及确定使用最合适的反馈机制。此外,他们还希望进一步探索如何最大限度地减少对人工注释的依赖,因为“大规模获取人工注释的成本很高”。

研究者计划进一步探索创建一个自动评估MT输入并决定是否需要后编辑的工作流程,同时寻找最合适的反馈机制以尽可能减少对人工注释的依赖。
